Introduction
This post describes the architecture we've built for serving large language model (LLM) inferences using a combination of:
- Nomad as the orchestrator
- Triton Inference Server with vLLM backend
- Envoy as the ingress/load balancer
- Consul for service discovery
- Prometheus + Nomad Autoscaler for observability and horizontal scaling
The goal was to design a serving stack that is modular, transparent, and responsive to traffic patterns — while remaining operationally simple.
High-level diagram of the architecture
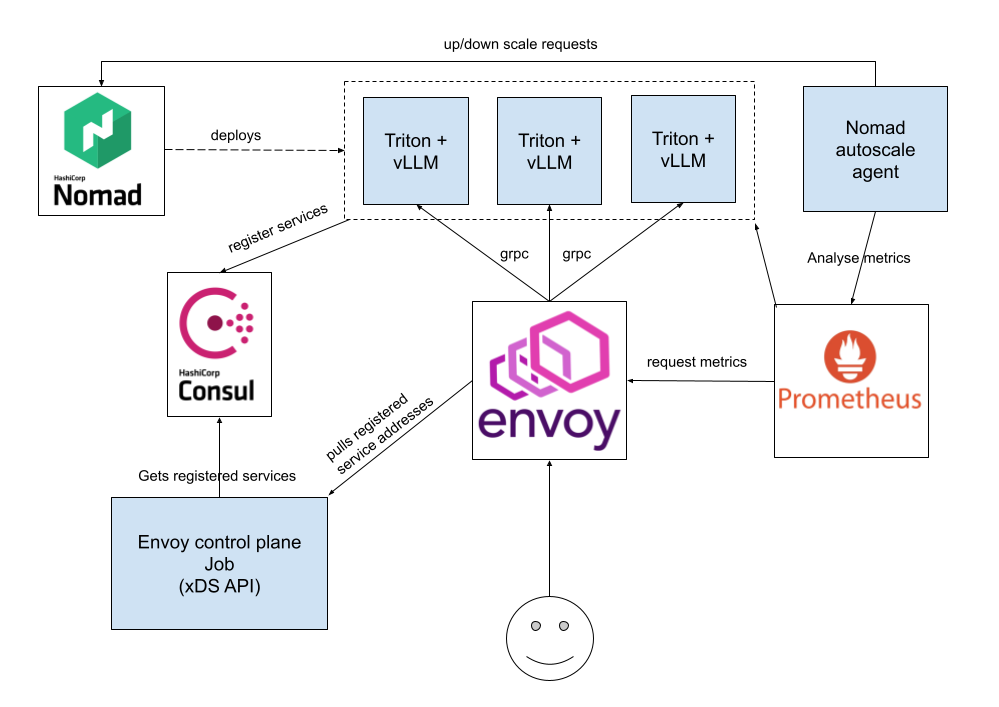
Architecture overview
Triton + vLLM backend via Nomad
Each model is deployed as a Nomad job running a containerized Triton Inference Server with vLLM backend. These jobs are registered in HashiCorp Consul, which we use for basic service discovery (we don't use Consul Connect or mesh features).
Envoy proxy + xDS Control Plane
All incoming inference requests go through Envoy, which serves as our load balancer.
Envoy is configured to:
- Load balance across Triton replicas using the Maglev algorithm.
- Forward requests via gRPC to Triton Inference Servers using Triton's native gRPC streaming interface.
Rather than hardcoding backend endpoints, Envoy retrieves them dynamically using the xDS API. We run a separate Envoy control plane (as a Nomad job), which:
- Pulls service data from Consul, where each Triton replica is registered.
- Generates a new xDS configuration snapshot.
- Serves that config to Envoy over xDS (Endpoint/Cluster/Listener Discovery Service).
This setup allows Envoy to stay up-to-date with available replicas and react to model deployments, restarts, or scale events — without requiring any restarts or manual updates.
Observability and Autoscaling
Prometheus scrapes the metrics from both:
- Envoy: request counts, error rates, latencies etc.
- Triton: inference performance.
To manage autoscaling, we've deployed a Nomad Autoscaler agent as a separate job. This agent continuously observes selected metrics—such as queued requests and system load—and uses Nomad's API to issue scaling instructions. Based on this data, it dynamically adjusts the number of replicas for each model job. This setup enables our services to scale horizontally in response to real-time demand, ensuring performance and resource efficiency.
Benchmarking
To evaluate our architecture, we ran end-to-end load tests comparing two setups for serving the 7b Multimodal model:
- Nomad + Envoy + Triton (vLLM backend)
- KubeAI + vLLM on Kubernetes
We tested various levels of concurrency and request volume to observe differences in response time, latency, and system stability.
| Concurrency | Total requests | Mean response time (KubeAI) | Mean response time (Nomad) | P95 Latency (Nomad) | Notes |
|---|---|---|---|---|---|
| 1 | 100 | 4.10s | 4.23s | 5.68s | Similar under light load |
| 5 | 100 | 4.12s | 3.50s | 4.37s | 15% faster on Nomad |
| 10 | 100 | 5.12s | 3.58s | 4.41s | 30% faster on Nomad |
| 25 | 500 | 4.77s | 3.63s | 4.52s | Nomad faster and stable |
| 50 | 500 | 5.05s | 4.56s | 6.95s | KubeAI latency starts to climb |
| 100 | 1000 | unstable | 5.30s | 6.94s | Nomad remained responsive |
Summary
This architecture provides a robust, scalable, and observable solution for serving LLM inferences. By combining Nomad for orchestration, Triton with vLLM for serving, Envoy for load balancing, Consul for service discovery, and Prometheus with Nomad Autoscaler for observability and scaling, we achieve a flexible and efficient system that adapts to changing traffic patterns and operational needs.